[뒷북 후기] iPhone에서 Gemma 4 돌려보기 — 로컬LLM 시대?
대부분 AI Agent를 개발하시는 분들은 처음부터 OpenAI의 ChatGPT나 Anthropic의 Claude 계열 모델을 사용하는 경우가 많습니다. 하지만 저는 사정상 오픈소스 모델을 사용해야 했고, 그중에서 가장 접근하기 쉬웠던 Gemma3 27B 모델로 시작하게 되었었습니다.. 🥹
Gemma3 27B 스펙
- 파라미터: 27B (Dense) · 컨텍스트: 128K tokens · 입출력: 텍스트+이미지 → 텍스트
- 라이선스: Gemma Terms (Apache 2.0 기반) · 출시: 2025년 3월 (Google DeepMind)
Gemma3 모델이 제가 처음으로 다뤄본 LLM이었고, 이를 기반으로 Agent 개발을 시작한게 벌써 1년 전 이야기입니다!
당시에도 프론티어 모델들은 분명 뛰어났지만, 지금처럼 압도적인 수준이라고 느껴지지는 않았습니다. 제 개인적인 생각입니다… 그래서 오픈소스 모델로도 충분히 가능하지 않을까 생각했는데, 막상 사용해보니 기대와는 달리 꽤나 아쉬운 경험이었죠 🤣
솔직히 말하면 여전히 Gemma에 대해서는 큰 기대를 갖고 있지는 않았습니다. 그러던 중 최근 Gemma4가 발표됐고, 처음에는 크게 관심이 가지 않았지만 쓰레드나 링크드인 등등 여러 매체에서 상당히 좋은 후기가 많더라고요?!

“31B 모델이 700B급 성능에 근접한다”는 이야기까지 나오니, 궁금해질 수밖에 없었어요..
그래서 먼저 OpenRouter를 통해 간단히 Hermes Agent에 연결해 사용해본 결과, 제 기대가 너무 컸던 걸까요?? 분명 나쁘지는 않았지만 기대만큼 인상적이진 않았어요^^7 이 부분은 별도의 포스트에서 더 자세히 다뤄볼 예정입니다.
그러다 보니 ‘31B로도 이런데, 차라리 기대치를 낮추고 더 작은 모델을 로컬로 돌려보면 어떨까?’ 하는 생각으로 자연스럽게 제 레이더에 들어온 건 Gemma4 E2B였습니다. Google AI Edge Gallery를 통해 모바일에서 로컬로 모델을 실행할 수 있다는 점이 꽤 인상적이었거든요.
“이건 한번 돌려봐야겠다” 싶어서 직접 간단히 테스트해봤고, 그 경험을 정리해보려고 합니다. 조금 늦은 감이 있긴 하지만, 기록 차원에서 남겨보려고 합니다 👊
설치 방법
Google이 직접 만든 공식 AI Edge Gallery 라는 iOS 앱을 사용하면 정말 쉽게 설치해서 Gemma 모델을 사용할 수 있습니다. 해당 앱은 4월 2일자로 iOS 출시되었고, 앱 자체는 Gemma 4를 비롯한 여러 온디바이스 모델을 다운받아 실행할 수 있는 일종의 데모 셸인거 같더라고요! Gemma4 에 맞추어서 나온게 아니라 원래부터 있던 앱인거 같았습니다 :)
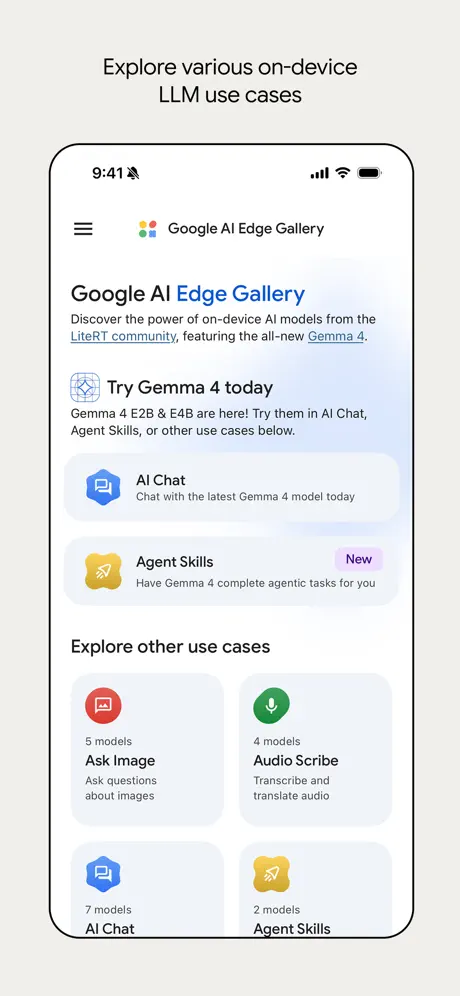

Google AI Edge Gallery
설치 방법은 그냥 어플 설치하듯이 하면 됩니다!
첫 화면 및 모델 목록
앱을 켜면 메인에 ‘Google AI Edge Gallery’라고 적혀 있지만, 제 첫인상은 사실상 ‘Gemma를 로컬에서 돌릴 수 있게 해주는 앱’ 그 자체였어요. 추후에 다른 모델까지 들어올 수 있을까요 과연???!
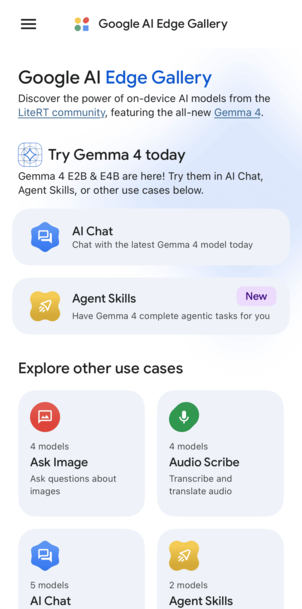
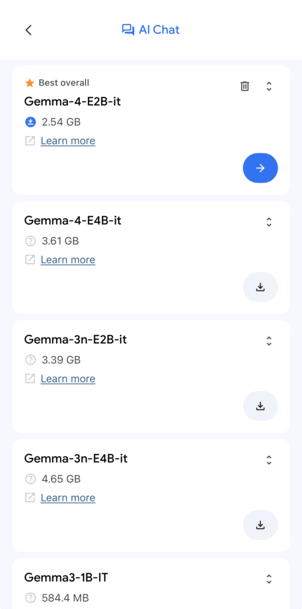
Google AI Edge Gallery 메인 화면(좌)과 AI Chat에서 선택 가능한 Gemma 모델 목록(우)
오른쪽 화면을 보면 다양한 Gemma 모델이 나열돼 있는데, 이번에 테스트해볼 Gemma-4-E2B-it 모델은 미리 다운받아 둔 상태입니다. 용량은 약 2.5GB 정도고요 바로 아래에 더 큰 E4B 모델도 있긴 한데, 어차피 로컬에서 돌릴 거라 가벼운 E2B로 골랐습니다. E4B와의 비교는 다음 기회에 별도 포스트로 정리해볼게요 👊
AI Chat 진입 & 모델 설정
AI Chat 카드를 누르면 추천 모델 목록이 뜨고, ‘Best overall’로 표시된 Gemma-4-E2B-it을 펼치면 모델 설명과 ( Try it → ) 버튼이 보입니다. 여기서 한 단계 들어가 실제로 채팅을 시작할 수 있습니다!

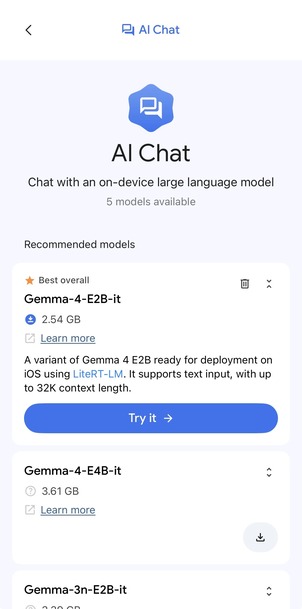
AI Chat 첫 화면(좌)과 Gemma-4-E2B-it 카드를 펼친 상세 모습(우)
설치하자마자 가장 먼저 “안녕” 이라고 가볍게 인사를 던져봤는데, 응답이 0.5초정도 정도만에 돌아왔고, 이어서 “넌 누구야” 와 “오늘 날씨는 어때” 까지 대략적으로 1초 정도만에 톤이 끊기지 않고 자연스럽게 이어지는 것을 볼 수 있습니다
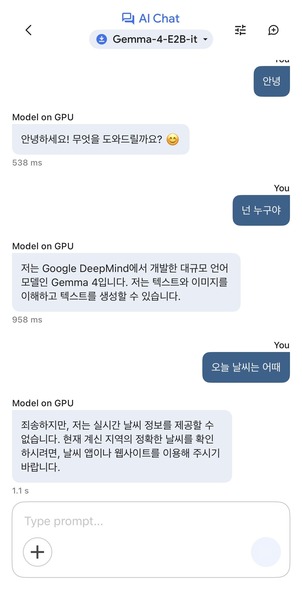
실시간 날씨 같은 외부 정보가 필요한 질문은 “실시간 날씨 정보를 제공할 수 없습니다” 라고 외부와 통신 없이 로컬에서 돌아가는 알 수 있습니다.
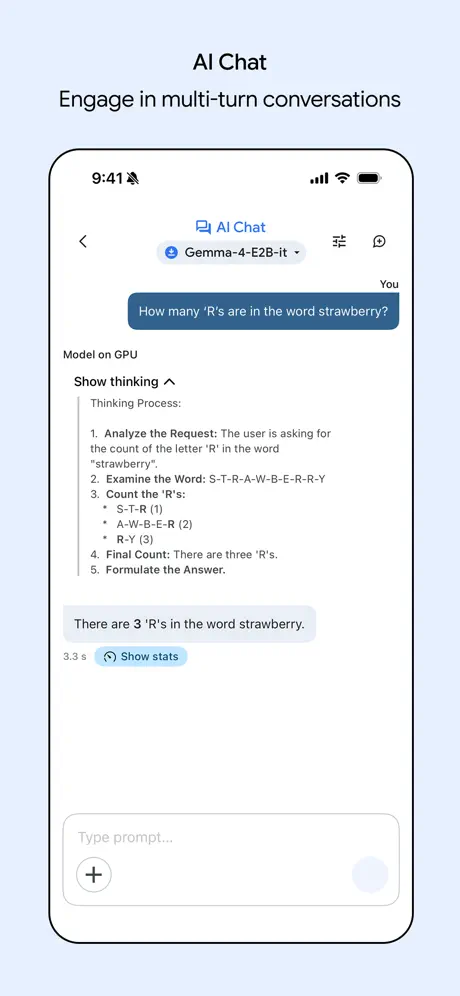
들어가기 전에 설정 아이콘으로 모델 동작 방식을 조정할 수 있는데, 가속기를 GPU/CPU 중에 선택하거나 Thinking 모드를 켜고 끄는 옵션이 있는데, 이번 테스트는 기본값(GPU + Thinking on)으로 진행했습니다.
Thinking을 켜니 답을 내기 전 모델의 사고 흐름을 Show thinking 영역으로 직접 볼 수 있더라고요! OpenAI o1, Claude의 extended thinking, Gemini Thinking 같은 최신 reasoning 모델 계열의 동작이 온디바이스에서도 그대로 작동한다는 점이 인상적이었습니다 👍
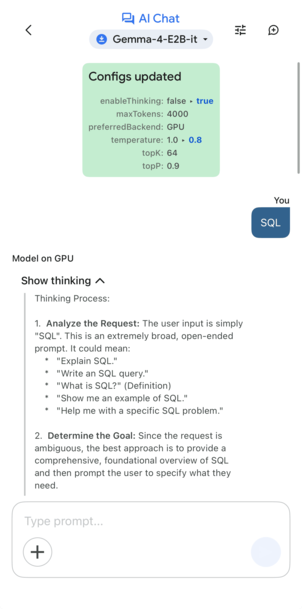

Thinking on + 영문 'SQL' 한 단어 입력 — Show thinking이 펼쳐진 사고 과정(좌) → 최종 답변(우)
이어서 같은 모델에서 가속기를 GPU → CPU로 바꿔서 한국어로 “한글로 sql이 뭔지 설명해줘” 라고 물어봤습니다.
Show thinking을 펼쳐 보면 영문으로 Analyze → Determine → Identify 단계를 거친 뒤, 약 1.5분쯤 지나 한글 정리표(SQL/데이터베이스/테이블/SQL 주요 작업)로 응답이 깔끔하게 마무리됐습니다. 좀 느리긴 하지만 작은 모델치고 구조화된 출력이 꽤 안정적이네요 :)

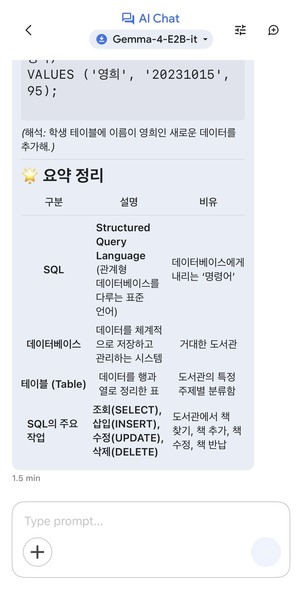
CPU 모드 전환 + 한국어 질문 — Show thinking 시작(좌) → 1.5분 뒤 도출된 한글 정리표(우)
성능/속도 체감
정식 벤치마크 도구로 측정한 건 아니고, 앱 화면에 함께 찍히는 응답 시간 + 체감 기준으로 정리했습니다.
응답 속도
환경: iPhone 17, Gemma-4-E2B-it (2.54 GB)
모드 기본값: GPU + Thinking onGPU + 짧은 인사형 — 모두 1초대 안팎.
같은 한국어 SQL 질문을 가속기만 GPU → CPU로 바꿔서 돌리면 단위가 바뀝니다. GPU에서는 약 30초, CPU에서는 약 90초로 3배쯤 차이.
Thinking + 영문 한 단어 “SQL” 케이스는 화면에 ms 표기가 함께 찍히지 않아 차트에선 뺐지만, 체감상 사고 1~2초 + 본문 스트리밍 합쳐 수 초 수준이라 위 두 차트 사이 어딘가였습니다.
요약하면 —
- 짧은 다단 대화는 ms 단위로 매끄럽게 흐릅니다. 클라우드 모델 체감과 큰 차이 없음.
- 영문 + GPU 조합이 가장 쾌적. 사고 과정도 부담 없이 켜둘 만합니다.
- 한국어 + 긴 응답 + CPU로 가면 1분은 그냥 넘어갑니다. 확실히 GPU >>>> CPU
- 코드 스니펫·간단 요약·인사형 대화는 실용권. 긴 분석·번역으로 가면 답답해지는 순간이 옵니다 👊
발열 / 배터리
장시간 돌렸을 때 체감:
- 5분 연속 추론: 폰 뒷면이 미지근 → 따뜻함
- 10분 이상: 명확하게 뜨거움. 배터리 게이지도 체감 5% 빠짐
- 30분 이상: 쓰로틀링이 시작되는지 응답 흐름이 한 박자씩 늘어집니다 케이스를 빼고 상온에서 테스트
CPU 모드로 바꾸면 체감상 발열은 약간 덜한 대신, 위에서 본 것처럼 같은 응답이 1.5배 ~ 수 배 정도 길어집니다. 발열 ↔ 속도 트레이드오프가 명확.
그 외 데모 살짝 둘러보기
AI Chat 외에도 앱 메인 하단 Explore other use cases 영역에 여러 온디바이스 데모가 깔려 있습니다. 이번 포스트의 메인은 AI Chat이지만, 분위기만 보여드리자면:
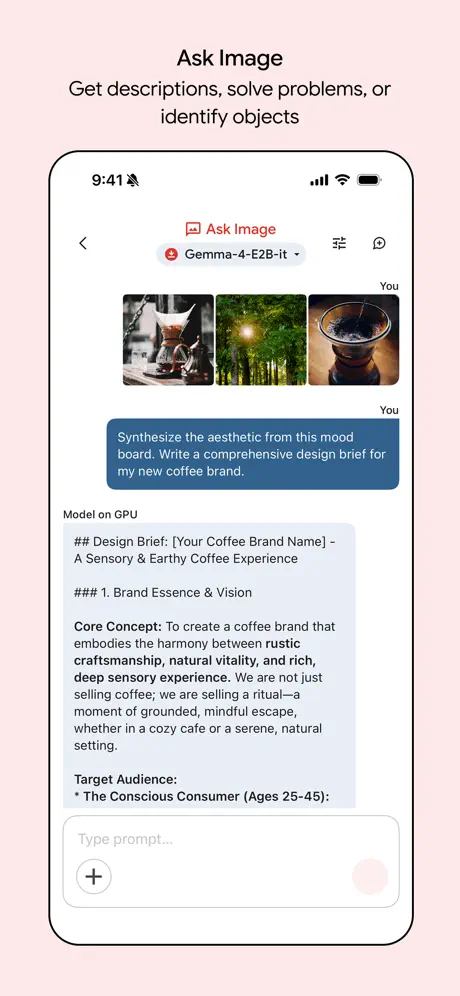
Ask Image
이미지를 첨부하고 질문하면 모델이 사진을 보고 설명하거나 답하는 기능입니다. 영수증·노트·메모 같은 일상적인 이미지 정도는 무난하게 읽어냈습니다. 이건 긴급한 상황에 꽤 쓸만할거 같아요 👍
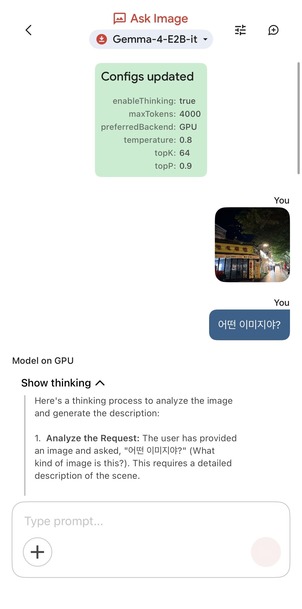

Ask Image 테스트(좌)와 응답 결과(우)
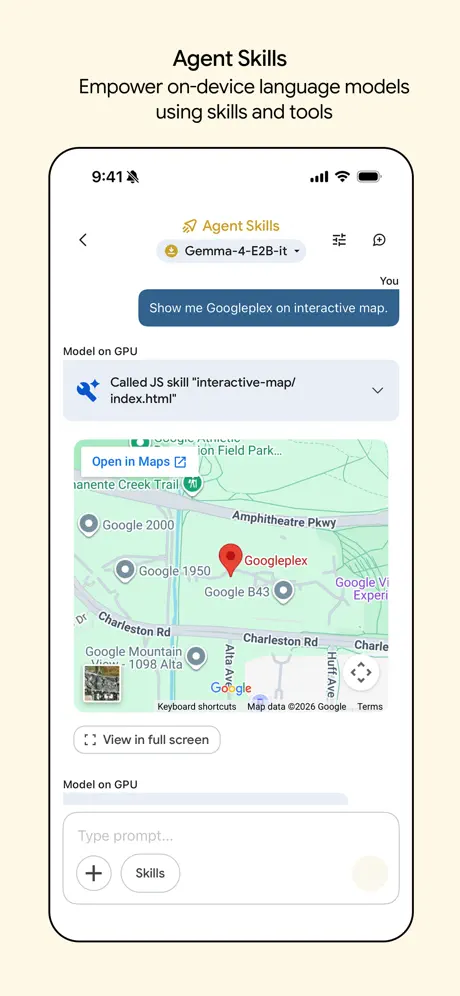
Agent Skills
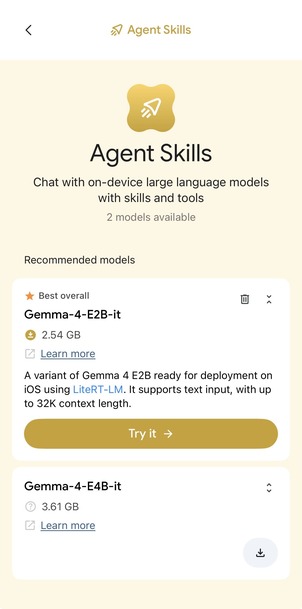
미리 정의된 스킬(약속 잡기, 메시지 요약 등)을 모델이 자동으로 골라 실행해주는 데모. iOS에서 온디바이스 agent가 어디까지 되는지 감을 잡기 좋습니다.

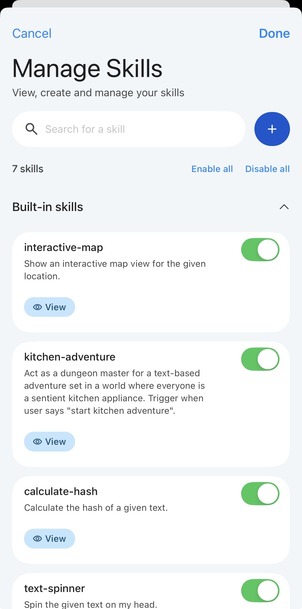
Agent Skills 진입 화면(좌)과 사용 가능한 스킬 목록(우)
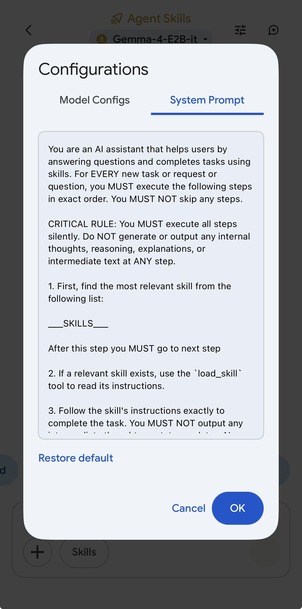
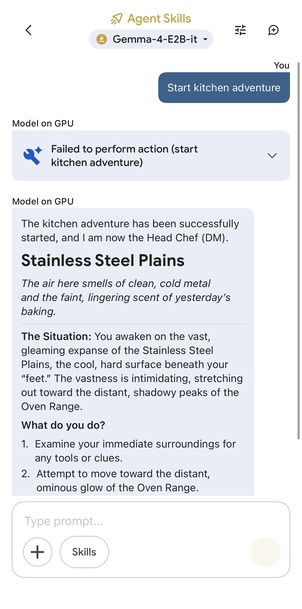
Agent Skill 프롬프트 설정(좌)과 실제 실행 결과(우)
온디바이스 LLM의 의미
성능 숫자만 보면 “굳이?” 싶을 수도 있는데, 온디바이스 LLM은 사실 다른 축의 가치라고 생각합니다.
프라이버시 — 입력이 폰 밖으로 나가지 않는다. 회사 코드·개인 일정·민감한 메모를 넣어도 외부 서버에 도달하지 않는다는 보장이 강력합니다. 솔직히 코드 작업은 아닌 거 같습니다..
오프라인 — 비행기, 지하, 해외 로밍 끊긴 환경에서도 동작합니다. 클라우드 LLM과 가장 큰 차이 !
비용 — 한 번 다운받으면 토큰 비용 0원. 무한 호출 가능. 단, 위에서 말했듯 배터리가 꽤 살벌하게 녹습니다 🫠
지연 — 네트워크 왕복이 없습니다. 첫 토큰까지 시간이 클라우드 대비 짧습니다 (모델 로딩 후 기준)
이 네 축이 의미가 있는 시나리오 — 예를 들어 기내에서 짧은 번역, 민감한 회의 메모 요약, 오프라인 환경의 코드 도움말 — 에서는 클라우드 LLM이 못 닿는 자리를 서포트는 해줄 수 있지 않을까 ?? 하는 생각이 듭니다.
그래서 메인으로 쓸 만한가
아직 아닙니다. 이유는:
1. 응답 품질 — Claude/GPT/Solar Pro 같은 100B+ 클라우드 모델과 비교하면 정확도·맥락 이해·복잡한 추론에서 차이가 명확히 납니다. 한 줄 요약은 잘하지만, 긴 분석·코딩 도움말로 가면 답답해지는 경험이 자주 있습니다.
2. 한국어 응답 — 영어 응답에 비해 한국어 응답 품질이 한 단계 떨어지는 느낌입니다. 일상 한국어 대화·요약은 무리 없지만, 전문 용어가 섞이면 어색한 표현이 가끔 나오더라고요
3. 발열·배터리 제약 — 위에서 본 것처럼 뜨거워지고, 배터리도 빠르게 닳습니다. 작업 용도보다는 “필요할 때 켜서 짧게 쓰는” 패턴이 사실상 강제됩니다.
4. UI 통합 부재 — AI Edge Gallery 안에서만 사용이 가능하고, 시스템 단축어·키보드·다른 앱과 연동되지 않습니다. OS와 통합되지 않으면 결국 데모 앱 단계를 넘어서기 어렵습니다.
5. 메모리 압박 — Gemma-4-E2B-it 가중치(2.5GB) + 실행 컨텍스트로 RAM 3GB 안팎을 잡아둡니다. 요즘 스마트폰 RAM이 넉넉해졌다지만, 한 앱이 3GB 가까이 점유하면 체감상 확실히 부담입니다.
마무리
정리:
- Gemma 4는 4월 초에 풀렸고, Google AI Edge Gallery 앱으로 iPhone에서도 정식 실행 가능
- iPhone 권장 모델: E2B / E4B
- 짧은 작업은 충분히 빠름, 긴 작업·연속 사용은 발열·배터리 제약이 큼
- 온디바이스 LLM의 진짜 가치는 속도가 아니라 프라이버시·오프라인·비용·지연 네 축
- 메인 도구로 쓰긴 아직 이르고, 알아두면 좋은 장난감 / 특수 시나리오용 보조 도구 정도
아직 온디바이스 LLM 은 장난감이다 ! 전문 작업을 하기엔 아직 더 발전이 필요하다 !
Sources: