[NL-to-SQL] Side Quest: Textual TUI에서 Jupyter Notebook으로 갈아타기
NL-to-SQL Agent (4부작)
- 1
- 2
- 3
- 4 [NL-to-SQL] Side Quest: Textual TUI에서 Jupyter Notebook으로 갈아타기 (현재 글)
![[NL-to-SQL] Side Quest: Textual TUI에서 Jupyter Notebook으로 갈아타기](https://objectstorage.ap-chuncheon-1.oraclecloud.com/n/axjvrbminfbt/b/thingk0-bloog/o/thumbnail%2F19.png)
지난 편
Quest 2에서 Textual TUI를 꽤 공들여서 만들었습니다. 4패널로 깔끔하게 나누고, @work 데코레이터로 비동기까지 챙겨놨으니 한동안은 잘 쓰겠지 싶었는데요…

문제는 TUI 자체가 별로였던 게 아니라 실험 환경의 요구사항이 달라졌다는 점이었습니다. Quest 3은 baseline ↔ RAG 두 결과를 나란히 두고 토큰·레이턴시·정확도 차이를 분석하는 작업인데,
TUI에는 그 비교를 위한 자리가 없습니다. 또 매 퀘스트마다 스크립트나 TUI를 새로 짜고 있으면 배보다 배꼽이 커지겠다 싶더라구요 😅
그러다 든 생각이, 그냥 Jupyter Notebook으로 옮기면 되지 않나? 싶었습니다. 셀 단위로 결과가 박제되고, 디버깅도 셀 하나씩 끊어 갈 수 있고, 무엇보다 두 파이프라인 결과를 나란히 놓고 DataFrame으로 굴리기에는 노트북이 훨씬 자연스럽습니다.
그래서 Quest 3 본격 시작 전에 환경부터 정리하기로 했습니다. 이번 사이드 퀘스트는 TUI를 내려놓고 Jupyter Notebook으로 옮긴 이유, 옮긴 후 노트북을 어떻게 구성했는지, 그리고 앞으로 실험 환경을 어떤 원칙으로 굴릴지 정리합니다.
Self-Contained 노트북 한 장
처음엔 src/에 있던 NaivePipeline 클래스를 그대로 import해서 노트북에선 pipeline.run(q) 한 줄만 쓸 생각이었는데, 막상 옮겨보니 셀 위에 있는 코드가 너무 추상화돼서 셀 안에서 무슨 일이 일어나는지 안 보였습니다. 학습용 노트북이라는 점을 감안하면 그게 더 큰 손해라서, 방향을 바꿨습니다 👍
| 노트북 | 흐름 |
|---|---|
quest1_semantic_rag.ipynb | Snowflake 스타일 YAML → 엔티티 분해 → Solar Embedding → pgvector 검색 |
quest2_naive_text_to_sql.ipynb | 스키마 introspection → zero-shot 프롬프트 → SQL 추출/검증/실행 → 20문항 평가 |
셀 1~4 — 환경 부트스트랩
매 노트북 머리에 동일한 패턴으로 시작합니다. %pip install로 패키지 설치컨테이너단 전역 설치도 가능하지만, 노트북마다 박아두는 쪽이 self-contained 원칙에 맞아서 그대로 둠
%pip install -q openai psycopg2-binary pgvector python-dotenv pyyaml pandas임포트 확인, 환경변수 점검(마스킹 포함), DB·Solar API 핑까지
def _mask(v, keep=4):
return (v[:keep] + "…" + v[-keep:]) if v and len(v) > keep * 2 else "<empty>"
required = ["UPSTAGE_API_KEY", "UPSTAGE_BASE_URL", "UPSTAGE_CHAT_MODEL",
"DB_HOST", "DB_PORT", "DB_NAME", "DB_USER", "DB_PASSWORD", "TARGET_SCHEMAS"]
missing = []
for k in required:
v = os.environ.get(k, "")
shown = _mask(v) if "KEY" in k or "PASSWORD" in k else v
print(f"{'OK ' if v else 'MISS'} {k:25s} = {shown}")
if not v: missing.append(k)
assert not missing, f"누락: {missing}"OutOK openai 2.36.0
OK psycopg2 2.9.12 (dt dec pq3 ext lo64)
OK pgvector n/a
OK dotenv n/a
OK yaml 6.0.3
OK pandas 3.0.2
python: 3.13.13
TUI에서는 시작할 때 환경변수 빠지면 그냥 죽었는데, 노트북에서는 셀 단위로 어떤 키가 비었는지 즉시 보입니다.
(Quest 1) 셀 5 — semantic_docs 테이블 상태 점검
Quest 1은 pgvector에 semantic_docs 테이블을 만들어 임베딩을 적재합니다. 한번 채워둔 임베딩을 매 실행마다 DROP/RECREATE 하면 임베딩 비용도 다시 들고 일관성도 깨지니까, 셀 5에서 존재 여부 + 호환성을 먼저 점검하고 이상 없으면 셀 6의 DDL을 건너뜁니다
with get_conn() as conn, conn.cursor() as cur:
cur.execute("SELECT to_regclass('public.semantic_docs');")
exists = cur.fetchone()[0]
if not exists:
print("semantic_docs 없음 → 셀 6 실행 필요")
else:
# 컬럼·임베딩 차원·인덱스 점검 후 OK면 다음 셀 스킵
...Outsemantic_docs 존재: semantic_docs
- id integer (int4)
- doc_id text (text)
- entity_type text (text)
- name text (text)
- title text (text)
- text_for_embedding text (text)
- keywords ARRAY (_text)
- metadata jsonb (jsonb)
- related_doc_ids ARRAY (_text)
- examples ARRAY (_text)
- source jsonb (jsonb)
- embedding USER-DEFINED (vector)
embedding 차원: 4096
Solar 모델 차원: 4096
OK 일치
기존 row 수: 165
인덱스 (6):
- idx_sd_entity_type
- idx_sd_keywords
- idx_sd_metadata
- idx_sd_name
- semantic_docs_doc_id_key
- semantic_docs_pkey
핵심은 셀 단위 멱등성(idempotent)입니다.
노트북 전체를 처음부터 끝까지 재실행해도 기존 임베딩이 보존되고, 인덱스/스키마 호환성이 셀 출력 한 줄에 모두 보이기 때문에 한 달 뒤에 봐도 “이 상태는 안전”임을 바로 알 수 있습니다. TUI에서는 이런 점검을 별도 명령어로 짜야 했을 텐데, 노트북에서는 상태 점검 셀 하나로 끝납니다 😆
(Quest 1) 셀 7 — 시맨틱 뷰 YAML 정의
Quest 1의 RAG 파이프라인은 “도메인 지식”을 통째로 한 곳에 모아둬야 합니다. Snowflake Semantic View 스타일 YAML 한 덩어리에 테이블·차원·시간차원·사실·메트릭·필터·관계·검증된 쿼리까지 다 넣어버립니다!
SEMANTIC_YAML = """
name: ecommerce_orders
description: 이커머스 주문 시맨틱 뷰
tables:
- name: orders
base_table: { database: nl2sql, schema: ecommerce, table: orders }
dimensions:
- { name: order_status, synonyms: [주문상태, 상태], expr: order_status, data_type: string }
time_dimensions:
- { name: order_date, synonyms: [주문일, 주문일시], expr: created_at, data_type: timestamp }
facts:
- { name: total_amount, synonyms: [주문금액, 결제금액], expr: total_amount, data_type: numeric }
metrics:
- { name: revenue, synonyms: [매출, 매출액], expr: SUM(total_amount) }
- { name: avg_order_value, synonyms: [객단가], expr: AVG(total_amount) }
filters:
- { name: completed_orders, synonyms: [완료된 주문], expr: "order_status = 'completed'" }
- name: customers
...
relationships:
- name: order_customer
left_table: orders
right_table: customers
relationship_columns:
- { left_column: customer_id, right_column: id }
metrics:
- { name: revenue_per_customer, synonyms: [고객별 매출], expr: SUM(total_amount) / COUNT(DISTINCT customer_id) }
verified_queries:
- name: monthly_revenue
question: 월별 매출 추이
sql: SELECT DATE_TRUNC('month', created_at) m, SUM(total_amount) FROM orders WHERE order_status='completed' GROUP BY 1
"""
yaml_data = yaml.safe_load(SEMANTIC_YAML)
print("view:", yaml_data["name"])
print("tables:", [t["name"] for t in yaml_data["tables"]])
print("relationships:", [r["name"] for r in yaml_data.get("relationships", [])])
print("view-level metrics:", [m["name"] for m in yaml_data.get("metrics", [])])Outview: ecommerce_orders
tables: ['orders', 'customers']
relationships: ['order_customer']
view-level metrics: ['revenue_per_customer']
이 YAML이 다음 셀들의 입력입니다. 같은 도메인 안에서 컬럼 추가나 메트릭 신설이 일어나면 이 YAML 한 군데만 손대고 셀 8~11을 다시 실행하면 끝 — ON CONFLICT DO UPDATE 덕분에 임베딩도 멱등하게 갱신됩니다.
synonyms 필드는 사용자 질문이 “객단가”든 “평균 주문 금액”이든 같은 avg_order_value 메트릭에 매칭되도록 RAG 검색을 도와줍니다. verified_queries는 Few-Shot 예시로 쓸 예정 (Quest 3에서).
(Quest 2) 셀 5 — 스키마 introspection (baseline의 핵심)
Naive baseline의 본체는 “전체 스키마를 통째로 프롬프트에 주입한다”입니다. 그래서 DB에서 직접 CREATE TABLE 모양으로 dump하는 셀이 필요합니다.
def introspect_schema(schemas: list[str]) -> str:
parts = []
with get_conn() as conn, conn.cursor() as cur:
cur.execute("""
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = ANY(%s) AND table_type='BASE TABLE'
ORDER BY 1, 2
""", (schemas,))
for sch, tbl in cur.fetchall():
# 컬럼 + PK + FK 조회해서 CREATE TABLE 모양 조립
...
return "\n\n".join(parts)
SCHEMA_TEXT = introspect_schema(os.environ["TARGET_SCHEMAS"].split(","))
print(f"... (총 {len(SCHEMA_TEXT)}자, {SCHEMA_TEXT.count('CREATE TABLE')}개 테이블)")Out-- ecommerce.brands
CREATE TABLE ecommerce.brands (
id integer NOT NULL,
name character varying NOT NULL,
description text,
country character varying,
created_at timestamp with time zone DEFAULT now(),
PRIMARY KEY (id)
);
...
-- ecommerce.coupons
CREATE TABLE ecommerce.coupons (
id integer NOT NULL,
code character varying
... (총 6881자, 18개 테이블)
이 셀 출력 한 줄로 “스키마가 몇 자고 몇 개 테이블인지” 바로 알 수 있다는 게 중요합니다. Quest 3에서 RAG가 토큰을 얼마나 줄였는지 비교할 때, baseline이 통째로 들고 다닌 글자 수가 셀에 박제돼 있으니 그냥 옆에 놓고 비교하면 됩니다 ✌️
셀 6~8 — 프롬프트 / SQL 추출 / 위험 키워드 차단
System/User 프롬프트를 분리하고, ```sql ... ``` 펜스를 정규식으로 뽑고, DROP·DELETE·UPDATE 같은 위험 키워드는 실행 전에 막습니다.
SYSTEM_PROMPT = """당신은 PostgreSQL 전문가입니다. ...
4. SELECT 쿼리만 작성하세요. DDL/DML(DROP, DELETE, ...)은 절대 사용하지 마세요.
5. SQL을 ```sql ... ``` 코드 블록으로 감싸서 출력하세요."""
FENCE_RE = re.compile(r"```(?:sql|SQL)?\s*\n(.*?)```", re.DOTALL)
DANGER_RE = re.compile("|".join([
r"\bDROP\b", r"\bDELETE\b", r"\bUPDATE\b", r"\bINSERT\b",
r"\bALTER\b", r"\bTRUNCATE\b", r"\bCREATE\b", r"\bGRANT\b", r"\bREVOKE\b",
]), re.IGNORECASE)
def is_safe_sql(sql: str) -> tuple[bool, str]:
cleaned = re.sub(r"--[^\n]*", "", sql)
cleaned = re.sub(r"/\*.*?\*/", "", cleaned, flags=re.DOTALL)
if (m := DANGER_RE.search(cleaned)):
return False, f"위험 키워드 검출: {m.group()}"
first = re.sub(r"\s+", " ", cleaned).strip().upper()
if not (first.startswith("SELECT") or first.startswith("WITH")):
return False, "SELECT/WITH로 시작 안 함"
return True, "OK"is_safe_sql만 따로 테스트 케이스 5~6개를 한 셀에서 돌려 OK/BLOCK 로그를 확인할 수 있습니다. TUI였으면 어딘가 로그 패널에 흘러가고 끝났을 텐데, 노트북에서는 코드와 검증 결과가 같은 셀에 묶입니다.
셀 9~11 — 실행기 + End-to-End 파이프라인 + 단일 질문
execute_sql은 SET LOCAL statement_timeout = 10000 으로 막아두고, 결과를 ExecResult dataclass로 감쌉니다. 그리고 그걸 run_pipeline이 GenResult + ExecResult로 합쳐 PipelineResult 한 개로 리턴하게 됩니다.
OutQ: 고객별 총 매출 상위 10명을 보여줘
SQL:
SELECT
c.id AS customer_id,
c.name AS customer_name,
SUM(o.total_amount) AS total_sales
FROM ecommerce.customers c
JOIN ecommerce.orders o ON o.customer_id = c.id
GROUP BY c.id, c.name
ORDER BY total_sales DESC
LIMIT 10;
-- exec: success=True, rows=10, 28.5ms
customer_id customer_name total_sales
0 167 김서현 16666258.88
1 76 류도현 16411577.87
2 417 김숙자 16273943.06
3 52 노경희 15001423.83
4 446 우서준 14216965.17
5 444 박수민 13839774.79
6 268 윤상훈 13779137.73
7 175 박지민 12689648.25
8 493 송채원 12643945.46
9 84 김지영 12551164.55
result = run_pipeline("고객별 총 매출 상위 10명을 보여줘", verbose=True)
result.df # ← 마지막 줄을 DataFrame으로 두면 셀에 HTML 테이블로 박힘마지막 줄의 result.df가 핵심입니다. TUI에서는 별도 DataTable 패널을 그려야 했는데, 노트북에서는 셀 마지막에 DataFrame만 두면 그대로 HTML로 출력됩니다 💪
셀 12~16 — 20문항 배치 + 메트릭 + 실패 케이스 + 저장
질문 리스트 20개를 한 셀에서 돌리고, 다음 셀에서 메트릭을 뽑고, 또 다음 셀에서 실패 케이스만 따로 출력하고, 마지막에 JSON으로 떨어뜨립니다.
for i, q in enumerate(QUESTIONS, 1):
r = run_pipeline(q)
status = "OK " if r.exec_success else "FAIL"
print(f" {i:2d}/{len(QUESTIONS)} {status} rows={r.row_count:>3} "
f"{r.elapsed_ms:>6.1f}ms {q[:30]!s}")
results.append(r)
# 다음 셀: 요약
ok = sum(1 for r in results if r.exec_success)
total_tokens = sum(r.prompt_tokens + r.completion_tokens for r in results)
print(f"실행 성공 : {ok}/{n} ({ok/n*100:.1f}%)")
print(f"전체 토큰 사용 : {total_tokens:,}")Out 1/20 OK rows= 1 10.9ms 전체 주문 건수
2/20 OK rows= 1 5.3ms 전체 고객 수
3/20 OK rows= 1 18.2ms 완료된 주문의 총 매출
4/20 OK rows= 25 21.1ms 월별 매출 추이
5/20 OK rows= 1 17.2ms 객단가 (평균 주문 금액)
6/20 OK rows= 10 17.1ms 고객별 총 매출 상위 10명
7/20 OK rows= 5 17.6ms 가장 최근 주문 5건
8/20 OK rows= 6 16.0ms 주문 상태별 건수
9/20 OK rows= 1 16.4ms 가장 비싼 주문 1건
10/20 OK rows= 1 6.4ms 최근 30일간 주문한 고객 수
11/20 OK rows=100 17.8ms 고객별 평균 주문 금액
12/20 OK rows= 1 9.7ms 매출이 가장 높은 월
13/20 OK rows=100 18.9ms 이름에 '김'이 들어가는 고객
14/20 OK rows= 1 6.3ms 주문이 한 번도 없는 고객 수
15/20 OK rows= 1 16.7ms 주문 금액이 평균보다 큰 주문 건수
16/20 FAIL rows= 0 15.8ms 고객당 평균 주문 횟수 (column "order_count" does not exist
LINE 4: AVG(order_co…)
17/20 OK rows= 57 15.7ms 올해 가입한 고객 목록
18/20 OK rows= 1 13.9ms 취소된 주문 비율
19/20 OK rows=100 21.2ms 요일별 주문 건수
20/20 OK rows= 1 8.7ms 가장 많이 주문한 고객 한 명
총 소요: 15.1s
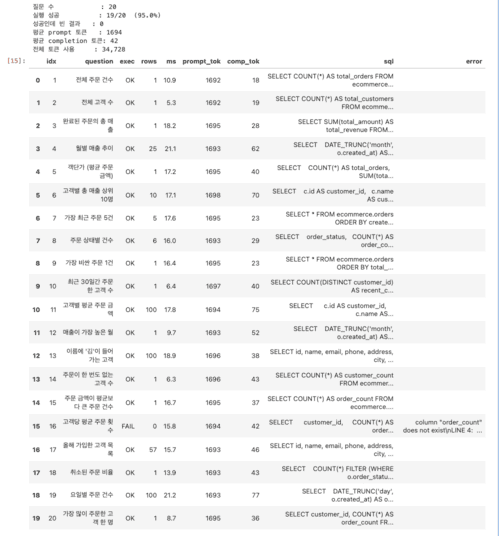
그리고 마지막 저장 셀입니다.
out_path = out_dir / f"quest2_baseline_{ts}.json"
payload = {
"timestamp": ts,
"model": os.environ["UPSTAGE_CHAT_MODEL"],
"schema_chars": len(SCHEMA_TEXT),
"exec_accuracy": ok / n,
"total_tokens": total_tokens,
"results": [{...} for r in results],
}
out_path.write_text(json.dumps(payload, ensure_ascii=False, indent=2))이 JSON이 Quest 3과 비교할 baseline 박제본입니다. 셀 안에서 실행→평가→직렬화까지 끝나니까, 한 달 뒤에 노트북을 열어도 “이 baseline은 이 모델, 이 스키마 글자 수, 이 토큰 양이었다”가 그대로 남아있습니다. 아주 굳이죠 👍
앞으로의 원칙: 실험·학습용은 모두 Jupyter
앞으로 프로덕트가 아닌 실험·학습·평가용 코드는 기본적으로 Jupyter Notebook으로 진행할 예정입니다.
- 프로덕트(서비스에 들어가는 코드): 모듈/패키지로 정리, 별개 트랙
- 실험·학습·평가: Jupyter + pandas + matplotlib 기본
- 데모·시연용: 필요할 때 TUI/Streamlit/CLI로 별도 빌드 아마 할 일이 없을 예정..
마무리
이번 사이드 퀘스트로 정리한 것:
- Textual TUI는 데모용으로 박제, 실험 환경은 Jupyter로 분리
- Quest 1/2 노트북을 self-contained 16셀 구성으로 다시 짜고, 출력은 셀 안에 그대로 박제
- baseline 메트릭(95% 성공률, 평균 1,694 prompt 토큰)을 JSON으로 떨궈서 Quest 3 비교 기준선 확보
- 들여쓰기·정렬 보존이 필요한 셀 출력은
<Out>컴포넌트로 렌더링
다음 편은 진짜 Quest 3. Quest 1의 retrieve()를 Quest 2의 프롬프트 자리에 꽂아서 baseline JSON 대비 토큰·exec accuracy 비교 들어갑니다.