Text-to-SQL은 시작일 뿐 — 워크플로우형 데이터 분석 에이전트를 만들어본 회고
한동안 워크플로우 형태의 에이전트가 궁금해서, 연구 삼아 직접 하나 굴려본 적이 있습니다. 자연어 질문을 받아 SQL · 차트 · 인사이트까지 뽑아내는 데이터 분석용 멀티 에이전트를 만들었었는데요, 지금은 다른 일에 밀려 미완성으로 접어둔 실험이지만, 그때 머리 싸맸던 설계 고민들이 꽤 남아 있어서 — 아쉬운 마음에 회고 삼아 기록을 남겨봅니다.

시작할 때 제 머릿속 그림은 단순했습니다. “자연어 → SQL → 결과”, 이거면 끝이라고 생각했죠. 근데 막상 만들어 보니 그건 전체의 일부에 불과하더라고요 🫠 하나씩 차근차근 풀어보겠습니다.
단순 Text-to-SQL로는 부족했다
처음 목표는 단순했습니다.
사용자 질문 → SQL 생성 → 실행 → 결과 반환근데 실제로 사용자들이 이러한 AI 에이전트한테 요청하는 방식은 이렇게 단순하지 않죠 보통!? 한 문장에 여러 의도를 욱여넣습니다.
“연도별 매출 추이를 차트로 보여주고 분석해줘.”
이 한 줄에 최소 네 가지 작업이 들어있다고 생각합니다.
- 의도 파악
- SQL 생성·실행
- 시각화
- 인사이트 설명
단일 에이전트 하나가 이걸 다 처리하게 만들면 프롬프트가 비대해지고, 한 군데만 틀어져도 전체가 무너질 수 있습니다. 그래서 하나의 거대한 에이전트 대신, 역할을 쪼갠 여러 에이전트를 의도에 따라 조합하는 구조로 해보기로 결정했습니다.
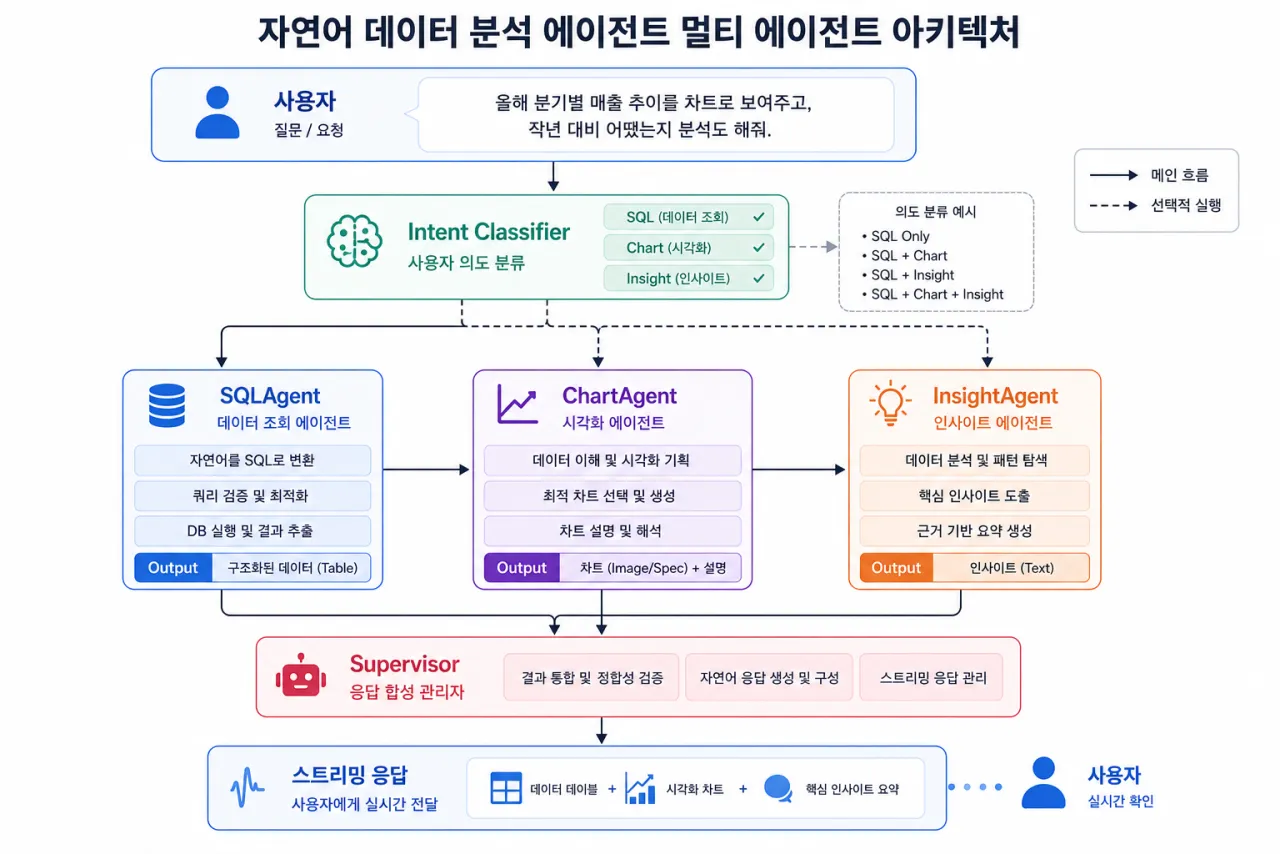
그래서 역할을 쪼갰습니다
중심에는 Supervisor 역할의 에이전트를 하나 뒀습니다. 질문이 들어오면 Supervisor가 의도를 분류하고, 그 의도에 맞는 최소 파이프라인만 실행합니다. 모든 질문에 매번 차트·인사이트까지 다 돌리지 않아도 됩니다.
| 의도 | 의미 | 실행 에이전트 |
|---|---|---|
query_only | 단순 조회 | SQLAgent |
visualization | 시각화 요청 | SQLAgent + ChartAgent |
analysis | 분석/해석 | SQLAgent + InsightAgent |
vis_analysis | 시각화 + 분석 | SQLAgent + ChartAgent + InsightAgent |
clarification | 질문이 모호함 | 되묻기 |

이렇게 나눠두니 특정 영역만 고치거나 갈아끼우기가 훨씬 편했습니다. SQL 품질만 손보거나, 차트 빌더만 확장하거나, 인사이트 프롬프트만 다듬거나 — 서로를 안 건드리고 작업할 수 있었어요 💪
LLM한테 다 맡기지 않았습니다
최근 LLM 들은 분명 강력하지만, 모든 판단을 LLM에 맡기면 시스템이 도박이 됩니다. 존재하지 않는 컬럼을 만들어내고, 데이터에 안 맞는 차트를 고르고, DB 방언에 없는 문법을 뱉을 수 있습니다.
그래서 LLM이 뱉은 결과를 그대로 믿지 않는 구조로 짰습니다.
대표적인 게 차트입니다. LLM에게 ECharts 옵션 형식과 데이터 컨텍스트를 프롬프트로 주입하고, Structured Output으로 차트 정의를 받았습니다. 그리고 받은 출력을 곧장 렌더링하지 않고 사후 검증·밸리데이션을 한 번 거칩니다. 형식이 깨졌거나, 데이터 타입에 안 맞는 차트를 골랐거나, 필드가 비어 있으면 거기서 걸러내는 거죠
LLM의 자유도는 살리되, 그 출력이 화면에 닿기 전에 코드가 한 번 더 검문하게 한 셈입니다. 이런 식으로 코드가 책임지는 영역을 넓게 가져갔습니다.
- 질문 명확성 검사 (너무 모호한 질문 거르기)
- 의도 1차 분류 (형태소 분석 + 정규식)
- 스키마 매칭 (“매출” →
sales컬럼 연결) - SQL 검증 (
DROP·DELETE차단, 없는 컬럼 참조 감지) - 차트 출력 검증 및 타입 fallback
- 데이터 프로파일링, 오류 메시지 변환
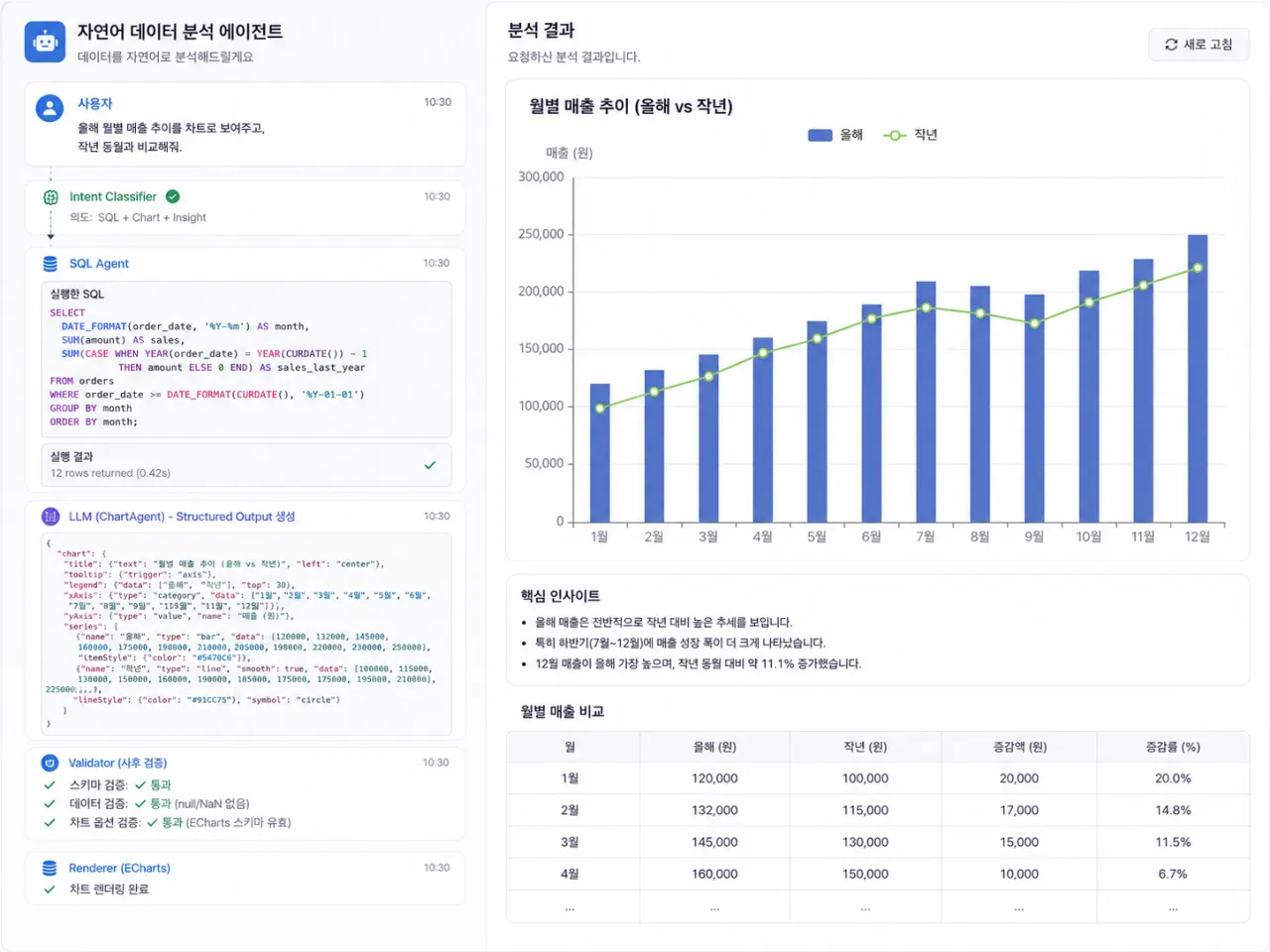
”생각 중”을 보여주는 스트리밍 UX
분석 질문은 처리에 생각보다 꽤 시간이 걸립니다. 그동안 화면이 멈춰 있으면 사용자는 “얘 죽었나?” 싶을 수도 있고, 사용자가 새로고침을 해버릴 수도 있습니다. 그래서 결과를 한 번에 던지지 않고, 단계별 진행 상황을 SSE 이벤트로 흘려보냈습니다.
예시)
info
think: 질문 의도를 분석하고 있습니다
think: SQL을 생성하고 데이터를 조회하고 있습니다
think: 120건의 데이터를 조회했습니다
think: 데이터를 시각화하고 있습니다
chart
text
sql
table
done덕분에 프론트엔드에서 “생각 중 → SQL 생성 완료 → 차트 표시 → 인사이트 작성” 같은 인터랙티브 UX를 자연스럽게 그릴 수 있었습니다✌️
또 하나는 [[TABLE]]·[[CHART]] 심볼 인터리빙입니다. 인사이트 텍스트 끝에 표·차트를 그냥 붙이는 게 아니라, LLM이 설명 흐름 중간에 심볼을 꽂으면 Supervisor가 그 자리에 실제 차트/테이블 이벤트를 끼워 넣습니다.
분기별 매출 추이를 보면 하반기 상승세가 뚜렷합니다.
[[CHART]]
세부 수치를 보면 4분기 매출이 가장 높습니다.
[[TABLE]]설명과 시각화가 자연스럽게 섞이니까 읽는 맛이 확 달라지더라고요.
심볼릭 방식이라 이점이 꽤 많았습니다. LLM은 무거운 차트 JSON·표 데이터를 다시 토해낼 필요 없이 [[CHART]] 한 줄만 꽂으면 되니 출력 토큰이 확 줄고 응답도 빨라졌고, 이미 계산해 둔 데이터를 그대로 재활용이 가능합니다. 무엇보다 LLM이 숫자를 다시 옮겨 적다 틀릴 일이 없었습니다. 설명은 LLM이, 수치는 코드가 책임지는 경계가 여기서도 그대로 유지됩니다 👍
LLM이 죽어도 굴러가게 — fallback
운영 환경에선 LLM API가 언제든 터질 수 있습니다. 온프레미스도 마찬가지겠죠? 갑자기 서버가 다운이 될 수도 있으니까요 그때 시스템 전체가 멈추면 안 되죠. 그래서 곳곳에 graceful degradation을 깔았습니다.
| 영역 | LLM 없거나 실패하면 |
|---|---|
| Chart | 데이터 형태를 보고 차트 타입을 자동으로 선택 |
| Insight | 인사이트는 건너뛰되 데이터·차트는 계속 반환 |
| Session | 저장소가 없으면 인메모리로 대체 |
예를 들어 차트는 “시간축 + 숫자면 꺾은선, 비중을 묻는 카테고리면 파이” 정도의 단순한 규칙만으로도 기본 시각화는 LLM 없이 처리됩니다.
만들면서 어려웠던 점
솔직히 힘들었던 건 결국 LLM의 불확실성을 시스템으로 길들이는 일이었습니다.
- 헛것 만들기: 없는 컬럼, 안 맞는 차트, 틀린 방언 문법 → 스키마 매칭 + SQL 검증 + 차트 출력 검증 + 재시도 + fallback을 단계적으로 쌓아 막았습니다.
- 의도 구분: “보여줘”·“봐줘”·“분석해줘”의 미묘한 차이를 키워드만으론 잡기는 애매합니다. 그래서 형태소 분석 → 정규식 → LLM fallback 순으로, 확신도가 낮을 때만 다음 단계로 넘기게 했습니다.
아쉬운 점 — 지금 다시 본다면
접어둔 실험이라 당연히 미완성입니다. 지금 코드를 다시 열어보면 눈에 밟히는 것들:
- 스키마 소스: 고정 샘플 스키마 / RAG 검색 / DB 자동 로딩 정도로 개념만 잡아뒀지,
information_schema자동 로딩이나 테이블 관계 추론은 손도 못 댔습니다. - 관측성: 의도 분류 정확도, SQL 실행 실패율, fallback 사용 비율, LLM 비용… 이런 걸 이벤트 단위로 모아야 개선 루프가 도는데, 로깅이 엉성합니다.

특히 인사이트 품질이 데이터 프로파일링과 프롬프트에 너무 의존하는 게 아쉬웠습니다. 통계 로직을 더 깔아서 LLM이 근거를 보고 해석하게 만들고 싶었는데 — 거기까진 못 가고 멈춘 게 제일 미련이 남습니다.
마무리
이 워크플로우 에이전트는 결국 “Text-to-SQL을 실제 분석 서비스 수준으로 끌어올리려면 뭐가 필요한가”에 대한 제 나름의 답이었습니다.
요즘은 LLM이 워낙 좋아져서, 단순한 ReAct 에이전트 여러 개에 룰과 프롬프트·컨텍스트만 적당히 나눠주고 멀티 에이전트를 만드는 사례를 많이 봤습니다. 근데 저는 그걸 볼 때마다 자꾸 걸리는 게 있었어요 — 비용이 너무 비효율적이고, 단계가 늘수록 환각도 같이 커지지 않나?
그래서 반대로 가봤습니다. 결정론적으로 처리할 수 있는 건 최대한 코드로 해결하고, 비결정론적인 부분만 LLM에게 맡기는 하이브리드 워크플로우가 더 옳다고 생각했습니다. 목표가 분명한 에이전트한테는 이쪽이 더 맞는다고 봤거든요.
재밌는 건 결과였습니다. 비교 대상은 흔히들 쓰는 비싸고 똑똑한 고성능 LLM + 단순 프롬프트 기반 ReAct 구성이었는데, 저는 LLM을 GPT-OSS-120B 같은 비용 효율적인 모델로 한참 낮춰 잡았어요. 그런데도 — 성능이 거의 비슷했습니다 물론 모델 자체의 한계선은 분명 있지만, “싼 모델로는 안 된다”가 절대적이진 않다는 걸 직접 확인했습니다.
저도 아직 배울 게 많고 부족합니다. 그래도 이 실험으로 하나는 분명해졌어요 — 모든 걸 LLM에게 떠넘기는 건, 적어도 목표가 분명한 시스템에선 좋은 선택이 아닐 수 있다.
완성까지 끌고 가진 못했지만, 이 워크플로우를 직접 짜보면서 얻은 감각은 지금 다른 에이전트를 볼 때도 계속 써먹고 있습니다. 미완의 실험이라도 남는 건 확실히 있더라고요 👍